SCHÄTZUNG DER SPRACHVERSTÄNDLICHKEIT
Instrumental intelligibility measures help to predict how much of the conveyed message in a speech signal can be understood by a listener. The majority of available instrumental speech intelligibility measures are intrusive, i.e. they rely on a clean reference signal for the intelligibility assessment of the corresponding noisy/processed signal at hand. Such measures use some type of SNR- or correlation-based comparison between the spectro-temporal representations of clean and processed speech. These criteria are used for measuring the effects of linear distortions as well as non-linear distortions. To utilize information theory for speech intelligibility prediction, novel instrumental intelligibility measures are introduced based on mutual information (MI). Furthermore, in order to allow for predicting speech intelligibility in the absence of the clean reference signal, a novel approach is introduced based on a speech recognition/synthesis framework called twin hidden Markov model (THMM).
SPRACHVERSTÄNDLICHKEITSMAßE BASIEREND AUF GEGENSEITIGER INFORMATION
MI is a general measure of dependence between two random variables that allows to account for higher order statistics, and hence to consider dependencies beyond the conventional second order statistics. MI can measure more complicated relationships between variables than linear relationships that correlation detects. On the other hand, it is well known that for the special case of Gaussian random variables MI depends solely on the correlation which is, in our application, fully determined by the signal-to-noise ratio. These features of MI imply that an instrumental measure based on MI can provide a unified viewpoint on existing instrumental measures.
In our model, amplitude envelopes of clean and processed speech are considered as realizations of a stochastic process. The auditory perception is evaluated by estimating MI between the temporal amplitude envelopes of the clean and processed speech in each frequency subband. By assuming that the average level of intensity is well above the hearing threshold in each subband, mutual information can help to detect distortions caused by non-linear processing which reduces the dependency between the temporal envelopes of the clean and processed speech.
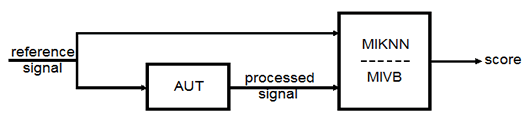
MATLAB code for two instrumental intelligibility measures MIKNN and MIVB are provided here. MIKNN and MIVB are different only in the method which is exploited for the MI estimation. The k-nearest neighbor (KNN) approach is used in MIKNN for estimating mutual information. MIVB uses a variational-Bayes based Gaussian mixture model for estimating the mutual information.
Both MIKNN and MIVB are intrusive (i.e., they require the clean and processed speech signals). It has been shown that instrumental intelligibility measures MIKNN and MIVB provide promising results for speech intelligibility prediction in different scenarios of speech enhancement where speech is processed by non-linear modification strategies.
[Download the Code]
References
- Jalal Taghia and Rainer Martin, “Objective intelligibility measures based on mutual information for speech subjected to speech enhancement processing”, IEEE Transactions on Audio, Speech, and Language Processing, vol. 22, no. 1, pp. 6-16, January 2014.
- Jalal Taghia, Richard C. Hendriks, and Rainer Martin, “On mutual information as a measure of speech intelligibility”, IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Kyoto, 2012.
Non-intrusive speech intelligibility prediction using THMMs

The twin hidden Markov model (THMM) is a statistical model originally introduced for audio-visual speech enhancement. Like conventional HMMs, the THMM is composed of a sequence of states modeling a time series of observations, e.g., the feature observation sequence of speech signals. However, in the THMM, each state is associated with two output density functions (ODFs): Recognition (REC) ODFs are used for modeling the distribution of features suitable for recognition (REC features), and synthesis (SYN) ODFs are employed for modeling the distribution of features appropriate for synthesis (SYN features). This ability of THMMs makes it possible to use the REC and the SYN features simultaneously for synthesizing a clean signal, leading to a model that can optimize both recognition and synthesis performance through an appropriate choice of features.
THMMs can be integrated into the framework of other intrusive intelligibility predictors and can compensate their problem of requiring the clean reference signal by estimating the relevant clean features from the noisy input signal. The experimental results show that the THMM can work very well in combination with the short-time objective intelligibility (STOI) measure, which is a well-known intrusive speech intelligibility prediction method.
Automatic speech recognition systems can be used directly to predict the listener's response to a speech signal on a word-by-word or phoneme-by-phoneme basis. Discriminance scores are extracted from HMMs trained for an ASR system and used as an intelligibility prediction feature. Such systems can be trained and used for both normal-hearing and hearing-impaired listeners' performance prediction.
In order to evaluate the performance of instrumental measures in predicting the listening performance of hearing impaired listeners, a database has been collected, which is available upon
request. It contains the listening test results of 9 hearing-aided listeners, who were asked to recognize keywords in speech utterances. The speech material was chosen from the Grid database and degraded using speech-shaped-noise in different SNRs. The audiogram data plus the results of the keyword recognition task have been recorded for each listener, separately.
References
- M. Karbasi, A. H. AbdelAziz, and D. Kolossa, “Twin-HMM-based non-intrusive speech intelligibility prediction,” in Proc. ICASSP 2016, Mar. 2016, pp. 624--628.
- M. Karbasi, A. H. Abdelaziz, H. Meutzner, and D. Kolossa, “Blind non-intrusive speech intelligibility prediction using twin-hmms,” in Proc. Interspeech 2016, Sep. 2016, pp. 625--629.
- M. Karbasi and D. Kolossa, “A microscopic approach to speech intelligibility prediction using auditory models,” in Proc. DAGA 2015, 2015, pp. 16--19.
- M. Cooke, J. Barker, S. Cunningham, and X. Shao, “An audiovisual corpus for speech perception and automatic speech recognition,” The Journal of the Acoustical Society of America, vol. 120, no. 5, pp. 2421–2424, November 2006.