Speech Enhancement in the DFT Domain
Speech Enhancement has been one of our research topics for several decades. There are many applications such as mobile voice communications, hearing aids, and human-machine interfaces - and there are many methods. We focus on noise reduction with the goal to improve listener comfort, listener fatigue, and to increase the intelligibility of the acoustic signal. We employ methods based on single microphone signals as well as multiple microphone signals (microphone arrays and beamforming). The development of speech enhancement methods requires a blend of physical modeling, statistical signal processing techniques, and deep learning. Most of our enhancement techniques operate in the spectral domain. Typically, the noisy speech signal is segmented into short frames, transformed, enhanced, inverse transformed, and overlap-added to reconstruct the enhanced signal (see Figure). The benefits of spectral processing are
- a concentration of speech energy in few spectral parameters (especially for voiced speech),
- a simpler statistical description as compared to the time domain, and
- possibly an application of psychoacoustic principles.
The block diagram of a typical system is shown below, [Martin et al., 2004].
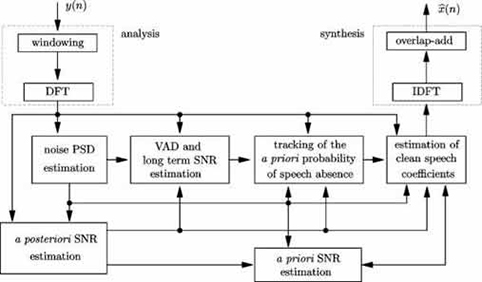
In what follows, we describe specific estimation and smoothing methods:
Noise power estimation
Temporal Cepstrum Smoothing
References
Breithaupt, C., Gerkmann, T., & Martin, R. (2008). A novel a priori SNR estimation approach based on selective cepstro-temporal smoothing. In 2008 IEEE International Conference on Acoustics, Speech and Signal Processing (pp. 4897–4900). IEEE. (https://doi.org/10.1109/ICASSP.2008.4518755)
Breithaupt, C., Gerkmann, T. & Martin, R. (2007). Cepstral Smoothing of Spectral Filter Gains for Speech Enhancement Without Musical Noise. IEEE Signal Processing Letters, 14(12), 1036–1039. https://doi.org/10.1109/LSP.2007.906208
Breithaupt, C., & Martin, R. (2003). MMSE estimation of magnitude-squared DFT coefficients with superGaussian priors. In 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, 2003. Proceedings. (ICASSP '03) (I-896-I-899). IEEE. (https://doi.org/10.1109/ICASSP.2003.1198926)
Madhu, N., Breithaupt, C., & Martin, R. (2008). Temporal smoothing of spectral masks in the cepstral domain for speech separation. In 2008 IEEE International Conference on Acoustics, Speech and Signal Processing (pp. 45–48). IEEE. (https://doi.org/10.1109/ICASSP.2008.4517542)
Martin, R. (2006). Bias compensation methods for minimum statistics noise power spectral density estimation. Signal Processing, 86(6), 1215–1229. Elsevier. (https://doi.org/10.1016/j.sigpro.2005.07.037)
Martin, R. (2005). Statistical Methods for the Enhancement of Noisy Speech. In J. Benesty, S. Makino, & J. Chen (Eds.), Signals and Communication Technology. Speech Enhancement (pp. 43–65). Springer-Verlag. (https://doi.org/10.1007/3-540-27489-8_3)
Martin, R., Malah, D., Cox, R. V., & Accardi, A. J. (2004). A Noise Reduction Preprocessor for Mobile Voice Communication. EURASIP Journal on Advances in Signal Processing, 2004(8), pp- 1046-1058. (https://doi.org/10.1155/S1110865704312138)
Martin, R. (2003). Statistical Methods for the Enhancement of Noisy Speech. Proc. Intl. Workshop Acoustic Echo and Noise Control (IWAENC) pp. 1-6.
Martin, R.; Lotter, T. (2001). Optimal recursive smoothing of non-stationary periodograms. Proc. Intl. Workshop Acoustic Echo Control and Noise Reduction (IWAENC).
Martin, R. (2001). Noise power spectral density estimation based on optimal smoothing and minimum statistics. IEEE Transactions on Speech and Audio Processing, 9(5), 504–512. (https://doi.org/10.1109/89.928915)
Martin, R. (1994). Spectral Subtraction Based on Minimum Statistics EUSIPCO-94, Edinburgh, Scotland, 13.-16. September 1994 pp. 1182-1185.
Martin, R. (1993). An Efficient Algorithm to Estimate the Instantaneous SNR of Speech Signals EUROSPEECH-93, Berlin, 21.-23. September 1993 pp. 1093-1096.