Privacy in Acoustic Sensor Networks
The ubiquity of portable smart devices along with the advent of the Internet of Things (IoT)have led to a wide dissemination of sensors. The presence of these sensors in everyday situations along with wireless connectivity and increasingly powerful machine learning algorithms pose an obvious risk to privacy. Obviously, these considerations are most relevant for microphones connected in an acoustic sensor network (ASN), for instance in a Smart Home environment.
In the figure below we provide an example of privacy risks encountered in ASNs that include a distributed processing scenario. Here, audio features extracted by the ASN nodes for the purpose of sound classification are transmitted to a cloud-based feature fusion and classification center. Concomitantly, they are intercepted by an attacker in order to be used for a more privacy-invasive task such as speaker recognition.
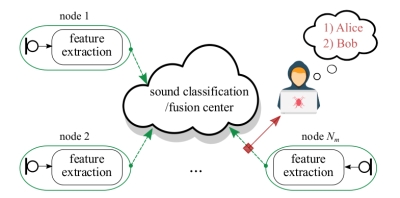
Illustration of privacy risks encountered in ASN scenarios that include distributed Processing. This figure is under the copyright of IEEE © in [1].
In order to mitigate ASN-related privacy risks and adhere to EU GDPR “privacy-by-design” regulations, we propose the use of privacy-preserving feature extraction schemes. In this case, extracted and transmitted features support specific desired ASN tasks but cannot be used for other purposes. These schemes require a balance between feature utility and feature privacy.
Privacy-preserving audio features
At the Institute of Communication Acoustics, researchers have developed privacy-preserving audio features that aim to improve the trade-off between feature utility and feature privacy.
One such feature extraction scheme is based on information minimization, where deep neural network (DNN) models are employed in conjunction with a mutual-information-based regularization criterion in order to produce a high-level feature representation that is suitable for trusted tasks but insufficient for more privacy-invasive purposes [1], [2].
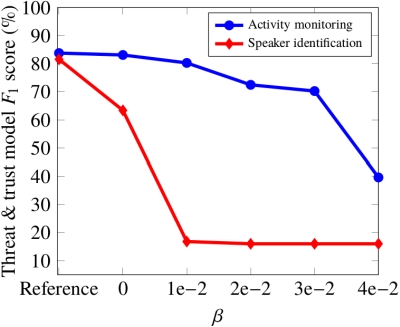
An illustration is provided in the figure below where the blue line indicates the performance of a domestic activity monitoring system deployed in a Smart Home environment and the red line indicates the performance of a speaker identification attack. The budget scaling factor 𝛽 is used to control the mutual-information-based regularization and, in turn, to optimize the privacy vs. utility trade-off. We can observe that for the mid range of values 𝛽 the speaker identification risks are significantly reduced with minimum impact on the trusted domestic activity monitoring task.
Privacy-preserving wake word verification
Many IoT applications based on ASNs include voice control via automatic speech recognition (ASR). This is usually performed on a server and activated by local wake word detection (WWD) approach. A common additional practice is wake word verification (WWV), where data is streamed to a server for an improved WWD decision. As indicated in the figure below, WWV implies inherent privacy risks such as eavesdropping where an attacker could intercept the transmitted data and perform ASR.
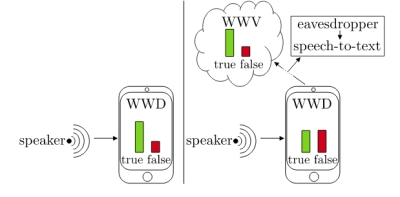
Privacy risks of wake word verification. This figure is under the copyright of ISCA © in [3].
Here, we address these privacy risks by employing adversarial training in conjunction with dimensionality reduction in order to develop a feature representation that minimizes ASR-based privacy risks while maintaining strong WWV performance. This is presented in the figures below where the word error rate (WER) of the attacker gradually increases as we increase the number of adversarial training iterations and as we decrease the dimensionality of the features. At the same time, the corresponding WWV performance is still preserved.
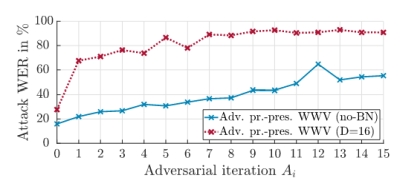
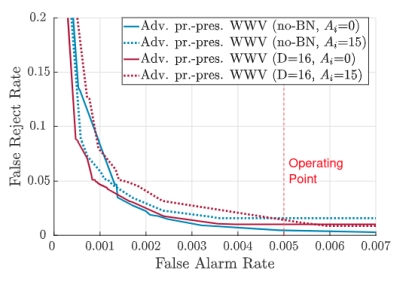
Privacy-preserving wake word verification. These figures are under the copyright of ISCA © in [3].
Privacy-preserving clustering of sensor nodes
In ASNs, clustering of acoustic sensors into groups dominated by a specific acoustic source offers many benefits to applications such as signal enhancement, event detection, source localization, etc. Considering modern privacy requirements and taking advantage of the computing capabilities of ASN nodes we propose unsupervised clustered federated learning for clustering ASN nodes around dominant sound sources [4], [5].
This consists of running a light-weight autoencoder at ASN node-level and transmitting only the DNN weight updates generated by each node in order to determine the clusters. In this case, the transmission of signal-related features into the network is avoided.
An example of clustering in a Smart Home where four speech sources are simultaneously active is presented in the figure below. The color intensity represents a node’s cluster membership value. It can be observed that our method is able to correctly identify clusters even in the rooms that do not host active sources (e.g., hallway, toilet).
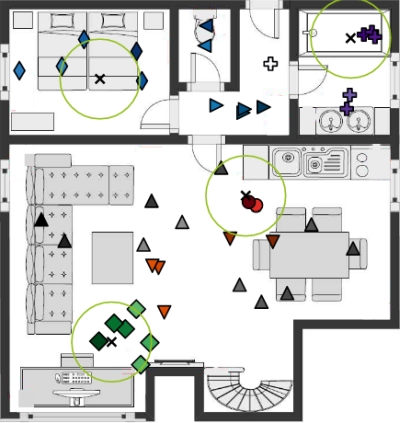
Unsupervised clustered federated learning in a complex multi-source acoustic environment.
References
[1] A. Nelus and R. Martin, “Privacy-preserving audio classification using variational information feature extraction,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 2864–2877, 2021
[2] A. Nelus, J. Ebbers, R. Haeb-Umbach, and R. Martin (2019), “Privacy-Preserving Variational Information Feature Extraction for Domestic Activity Monitoring versus Speaker Identification,” in Proc. Interspeech 2019, 2019, pp. 3710–3714
[3] T. Koppelmann, A. Nelus, L. Schönherr, D. Kolossa, and R. Martin (2021), “Privacy- Preserving Feature Extraction for Cloud-Based Wake Word Verification,” in Proc. Interspeech 2021, 2021, pp. 876–880
[4] A. Nelus, R. Glitza, and R. Martin (2021), “Unsupervised clustered federated learning in complex multi-source acoustic environments,” in 29th European Signal Processing Conference, EUSIPCO 2021. IEEE, 2021
[5] A. Nelus, R. Glitza, and R. Martin (2021), “Estimation of microphone clusters in acoustic sensor networks using unsupervised federated learning,” in IEEE International Confer- ence on Acoustics, Speech and Signal Processing, ICASSP 2021, Toronto, ON, Canada, June 6-11, 2021. IEEE, 2021, pp. 761–765
[6] A. Nelus and R. Martin (2019), “Privacy-aware feature extraction for gender discrimination versus speaker identification,” in IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2019, Brighton, United Kingdom, May 12-17, 2019. IEEE, 2019, pp. 671–674
[7] A. Nelus and R. Martin (2018), “Gender Discrimination Versus Speaker Identification Through Privacy-Aware Adversarial Feature Extraction,” in Speech Communication; 13th ITG-Symposium, Oct 2018, pp. 1–5
[8] A. Nelus, S. Gergen, J. Taghia, and R. Martin (2016), “Towards opaque audio features for privacy in acoustic sensor networks,” in Speech Communication; 12. ITG Symposium; Proceedings of. VDE, 2016, pp. 1–5