Selective Temporal Cepstrum Smoothing for Speech Enhancement
Many
speech enhancement algorithms that modify short-term
spectral magnitudes of the noisy signal are plagued
by annoying spectral outliers that are perceived as
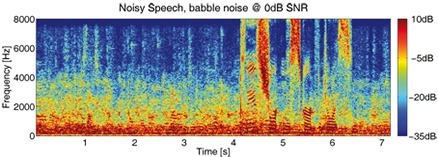
musical noise. Especially in nonstationary noise, such
as babble-noise or street noise, musical noise artifacts
have been an unsolved problem over the last decades.
To reduce spectral outliers certain parameters of the
speech enhancement algorithm, such as the a priori SNR
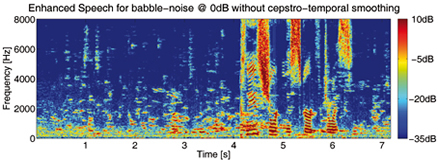
or the gain function, should be smoothed. However, while
a temporal smoothing in the frequency domain reduces
spectral outliers, it also results in a distortion of
speech onsets and low energy speech components. A better
performance can be achieved by applying temporal smoothing
in the cepstral domain. The cepstral domain is defined
as the inverse Fourier transform of the logarithm of
the spectral magnitude. In the cepstral domain, the
signal is decomposed into the spectral envelope (lower
cepstral coefficients) and the spectral fine structure
(upper cepstral coefficients). Speech will be mainly
represented by the low cepstral coefficients and a cepstral
peak in the upper cepstrum that represents the pitch
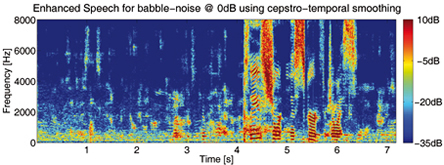
information. A selective temporal smoothing in this
domain can be applied, i.e. no or little smoothing to
the speech related cepstral coefficients, and strong
smoothing to the remaining coefficients.
The benefits of a selective cepstrum smoothing are that
- speech onsets are preserved
- the speech spectral envelopes of plosives and fricatives are preserved
- spectral harmonics of low energy are preserved
- the musical noise phenomenon is greatly reduced
Even in babble-noise a selective cepstrum smoothing
strongly reduces the musical noise phenomenon without
distorting the speech signal. Listening experiments
and instrumental measures consistently indicate improvements
in terms of overall quality, speech quality, noise quality,
noise reduction, spectral distortion and signal-to-noise
ratio.
A selective cepstrum smoothing can be applied to any
speech enhancement algorithm in that the input spectrum
is weighted by a gain function. In speech separation
often binary spectral masks are applied. A selective
temporal smoothing of the spectral masks in the cepstral
domain was shown to greatly improve the overall and
background quality of speech separation algorithms.
![]()