ABSTRACT
Most approaches for speech signal processing rely solely on acoustic input, which has the consequence that spectrum estimation becomes exceedingly difficult when the signal-tonoise ratio drops to values near 0 dB. However, alternative sources of information are becoming widely available with increasing use of multimedia data in everyday communication. We suggest to use video input as an auxiliary modality for speech processing by applying a new statistical model – the twin hidden Markov model. The resulting enhancement algorithm for audiovisual data greatly outperforms the standard audio-only log-MMSE estimator on all considered instrumental speech quality measures covering spectral and perceptual quality
THMM-based audio-visual speech enhancement
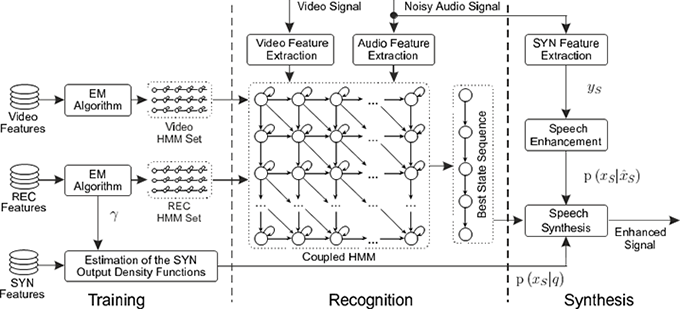
Framework of the twin-HMM-based audio-visual speech enhancement (THMMB-AV-SE)
Examplary Results
 |
 |
 |
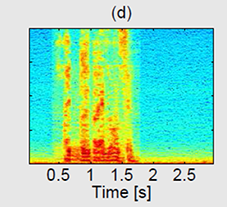 |
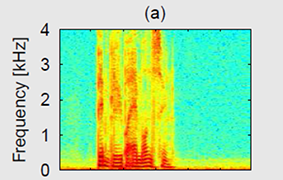
(a) Spectrum of the GRID sentence "BIN BLUE BY M ONE SOON" uttered in clean conditions.
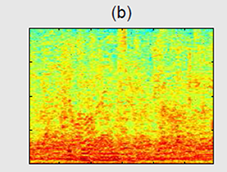
(b) The same sentence with added babble noise at 0 dB SNR.
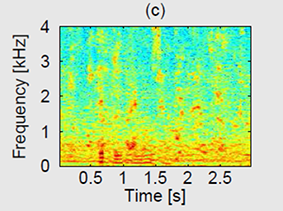
(c) The log-MMSE enhanced spectrum.
(d) The filtered noisy spectrum after THMMB-AV-SE.
Instrumental Quality Measure
Evaluation of twin-HMM-based speech processing in terms of segmental SNR, perceptually motivated quality measures PESQ (Perceptual Evaluation of Speech Quality), and STOI (Short Term Objective Intelligibility measure)
| Noise | S-SNR | PESQ | STOI | ||||||||||
| Type | SNR [dB] | Unpro- cessed |
Log- MMSE |
T-HMM | Unpro- cessed |
Log- MMSE |
T-HMM | Unpro- cessed |
Log- MMSE |
T-HMM | |||
| White | 15 | 0.11 | 1.83 | 5.35 | 2.37 | 2.69 | 3.02 | 0.89 | 0.87 | 0.91 | |||
| 10 | -2.22 | -0.39 | 2.66 | 2.08 | 2.36 | 2.68 | 0.82 | 0.80 | 0.85 | ||||
| 5 | -4.27 | -2.42 | -0.08 | 1.82 | 2.03 | 2.31 | 0.73 | 0.71 | 0.75 | ||||
| 0 | -5.98 | -4.27 | -2.49 | 1.63 | 1.72 | 1.93 | 0.64 | 0.62 | 0.63 | ||||
| Jet | 15 | 0.12 | 0.79 | 4.37 | 2.47 | 2.77 | 3.04 | 0.90 | 0.88 | 0.92 | |||
| 10 | -2.20 | -1.49 | 1.60 | 2.18 | 2.44 | 2.71 | 0.83 | 0.80 | 0.85 | ||||
| 5 | -4.26 | -3.30 | -1.11 | 1.89 | 2.10 | 2.31 | 0.72 | 0.69 | 0.73 | ||||
| 0 | -5.98 | -4.77 | -3.35 | 1.67 | 1.81 | 1.90 | 0.61 | 0.59 | 0.60 | ||||
| Babble | 15 | 0.35 | 0.69 | 3.99 | 2.71 | 2.88 | 3.05 | 0.93 | 0.90 | 0.94 | |||
| 10 | -1.99 | -1.75 | 1.18 | 2.41 | 2.59 | 2.74 | 0.87 | 0.83 | 0.88 | ||||
| 5 | -4.10 | -3.52 | -1.39 | 2.07 | 2.26 | 2.35 | 0.76 | 0.73 | 0.78 | ||||
| 0 | -5.88 | -4.96 | -3.71 | 1.78 | 1.91 | 1.95 | 0.63 | 0.60 | 0.63 | ||||
| Clean | - | 35.00 | 17.59 | 18.54 | 4.50 | 4.32 | 4.33 | 1.00 | 1.00 | 1.00 | |||